
The AI Project Cycle is the structured process used to develop artificial intelligence models that solve real-world problems. From defining an objective to deploying a fully functional AI system, this cycle ensures efficiency, accuracy, and innovation. But why is this cycle so important?
Imagine constructing a smart home assistant without a well-defined development plan. If you jump straight into programming without collecting the right data or testing the model properly, the assistant might misinterpret user commands, provide incorrect responses, or even fail completely. The AI Project Cycle helps prevent such issues by breaking the process into clear, manageable stages.
In this guide, we’ll break down each step of the AI Project Cycle, explaining how AI models are built, trained, and deployed. Whether you’re a beginner or an AI enthusiast, this step-by-step guide will simplify the process and help you understand how AI solutions come to life.
What is the AI Project Cycle?
The AI Project Cycle is a step-by-step framework used to develop AI models, ensuring they are properly designed, trained, and optimized before being deployed for real-world use.
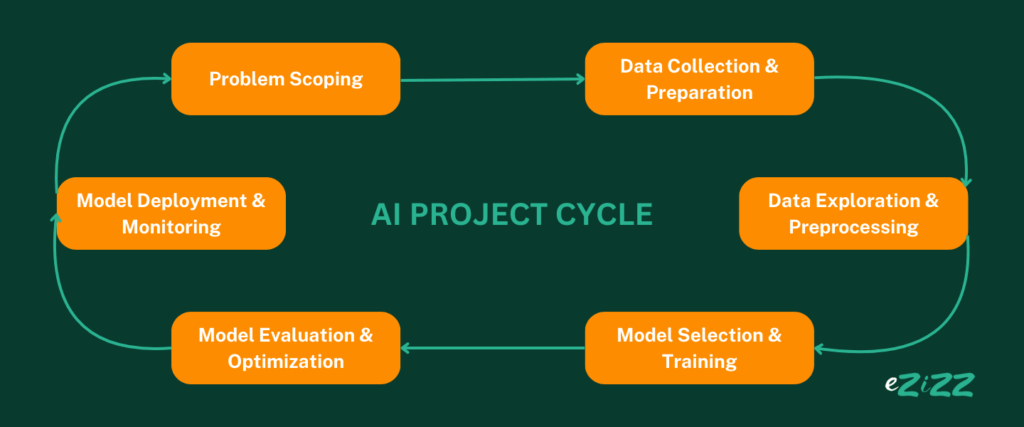
Why is the AI Project Cycle Important?
- AI isn’t just about cool technology—it’s about solving real problems in the smartest way possible!
- It helps businesses tackle real-world challenges with precision.
- Reduces costly mistakes by improving AI accuracy.
- Makes AI development faster, smoother, and more efficient.
Let’s explore AI Project Cycle’s each stage in detail!
1. Problem Scoping
Before building an AI system, the first and most crucial step is to clearly define what problem you’re trying to solve. This is known as Problem Scoping. If you don’t fully understand the problem, the AI system you create might end up being useless or even misleading. To identify the problems we can follow the 4Ws problem canvas i.e., Who, What, Where and Why. 4Ws problem canvas can helps in getting clear problems picture in detail.
The 4Ws Problem Canvas for Problem Scoping
To define the problem effectively, ask yourself:
- What is the issue that needs solving? (e.g., Predicting customer churn for a subscription business)
- Who is affected by this issue? (e.g., Customers, business owners, sales teams)
- Why is solving this problem important? (e.g., Preventing revenue loss, improving customer experience)
- What results would indicate success? (e.g., A 15% improvement in churn prediction accuracy)
Example:
Let’s say an e-commerce company wants to build an AI system to recommend products to users. Without proper problem scoping, they might train their model on outdated data or fail to consider seasonality in shopping trends. However, by applying the 4Ws framework, they can ensure that their AI system is trained on the right data, for the right users, in the right context.
2. Data Collection & Preparation
Once you have a well-defined problem, the next step is to collect high-quality data that will be used to train your AI model. AI is only as good as the data it learns from, so this step is critical for success.
Think of it like teaching a child. If you want them to recognize different dog breeds, you wouldn’t show them just one type of dog—you’d show them various breeds, colors, and sizes to help them understand patterns. Similarly, an AI system needs diverse, high-quality data to make accurate predictions.
Types of Data Used in AI
AI models typically rely on two types of datasets:
- Training Data : It is used to “teach” the AI model patterns and relationships.
- Testing Data : Testing data is used to evaluate how well the trained model performs on unseen data.
In some cases, a third dataset called Validation Data is used to fine-tune the model before final testing.
Methods to Collect Data:
- Surveys & Questionnaires : Collecting responses from users (e.g., customer satisfaction surveys).
- Web Scraping : Extracting data from websites (e.g., gathering product prices from competitors).
- APIs (Application Programming Interface) : Using third-party data sources (e.g., weather APIs for predicting sales trends).
- Sensors & IoT Devices : Collecting real-time environmental data (e.g., temperature, humidity, motion sensors).
- Government & Open Data Portals : Reliable data sources like data.gov, WHO, NASA.
Example:
For our e-commerce return prediction AI, we collect customer reviews, past return data, and product quality ratings.
Challenges in Data Acquisition
Despite having multiple data sources, collecting clean, usable data isn’t always easy. Here are some common challenges:
- Data Privacy Issues : Laws like GDPR and CCPA restrict how user data can be collected and used.
- Missing or Incomplete Data : Some datasets may have gaps, leading to inaccurate AI models.
- Data Bias : If the dataset isn’t diverse, the AI model may favor certain groups unfairly.
Tip : Always clean, preprocess, and validate your data before using it to train AI models.
People also read about What is the Main Goal of Generative AI?
3. Data Exploration & Preprocessing
Once you have collected your data, you need to analyze and preprocess it before training the AI model. Data is often messy, inconsistent, or full of errors. Data Exploration helps:
- Identify trends and patterns : Understanding relationships between variables.
- Detect missing values or errors : Fixing gaps before model training.
- Choose the right preprocessing techniques : Scaling, normalizing, or transforming data.
Techniques for Data Exploration & Preprocessing
- Data Visualization : Using bar charts, scatter plots, and histograms to spot trends.
- Handling Missing Data : Filling in gaps using mean, median, or predictive methods.
- Feature Engineering : Creating new features that enhance model performance.
Example:
If you’re predicting house prices, a feature like “Distance to nearest school” might improve model accuracy.
4. Model Selection & Training
At this stage, we finally bring AI to life! AI modeling refers to the process of teaching an AI system how to recognize patterns, make predictions, or automate decisions based on the data it has learned. This is where raw data is transformed into a functional AI system.
Imagine you’re building a spam detection AI. The AI model needs to analyze thousands of emails labeled as “spam” or “not spam” and learn which words, patterns, or sender behaviors indicate spam. This training allows the AI to identify spam emails automatically in the future.
Types of AI Models
Different AI models are used depending on the problem being solved. Here are the most common types:
Supervised Learning (For labeled data)
- Used when input data is labeled (e.g., classifying spam emails).
- Common algorithms: Linear Regression, Decision Trees, Random Forest, Neural Networks.
Unsupervised Learning (For discovering hidden patterns)
- Used when data is unlabeled and AI must find patterns itself (e.g., customer segmentation).
- Common algorithms: K-Means Clustering, PCA, Autoencoders.
Reinforcement Learning (For decision-making in dynamic environments)
- AI learns from trial and error by receiving rewards or penalties (e.g., self-driving cars, game-playing AI).
- Common techniques: Q-Learning, Deep Q Networks (DQN), Proximal Policy Optimization (PPO).
How to Choose the Right AI Model?
Selecting the best AI model depends on:
- The type of data : Is it labeled (supervised) or unlabeled (unsupervised)?
- The problem domain : Are you predicting numbers (regression) or classifying objects (classification)?
- Computational power – Simple models require less processing; deep learning models need GPUs/TPUs.
Training the AI Model
- Overfitting : When a model performs too well on training data but poorly on new data.
- Underfitting : When a model fails to capture meaningful patterns.
- Bias in Data : If trained on biased data, AI may make unfair decisions (e.g., racial bias in hiring AI).
To avoid these issues, data balancing, feature selection, and model evaluation are crucial.
Example:
For demand prediction, an LSTM neural network (used in time-series forecasting) is trained on past sales data to detect trends.
5. Model Evaluation & Optimization
Once a model is trained, we must test its accuracy and reliability before deploying it in the real world. This step prevents AI from making incorrect, biased, or unpredictable decisions.
Imagine deploying a fraud detection AI in a bank without proper evaluation. If the model is flawed, it may wrongly block genuine transactions or miss actual fraud cases, leading to financial losses.
Key Performance Metrics for AI Models
Accuracy
Accuracy measures the percentage of correct predictions. It is good for balanced datasets.
Precision & Recall (Important for AI models in healthcare, fraud detection, etc.)
- Precision : It measures how many predicted positive cases were actually correct.
- Recall : It measures how many actual positive cases were correctly identified.
Example: In cancer detection AI, high recall is critical because missing a cancer case is dangerous.
F1-Score
A balance between Precision & Recall. Useful for imbalanced datasets.
Confusion Matrix
A table that shows how well an AI model classifies different categories. Used to identify errors and improve model performance.
Example:
A loan approval AI at a bank must: Approve creditworthy customers and Reject risky applicants. If the model wrongly approves bad applicants, the bank loses money. If it wrongly rejects good applicants, the bank loses customers. Proper evaluation helps find this balance.
6. Model Deployment & Monitoring
Once an AI model is tested and refined, it’s time to deploy it for real-world use. This involves:
- Integrating AI with business applications (e.g., embedding AI into customer support chatbots).
- Using cloud platforms like AWS, Azure, Google Cloud for large-scale deployment.
- Monitoring model performance in real-time to detect errors or biases.
Challenges in AI Deployment
- Scalability Issues : AI models need powerful servers for real-time predictions.
- Data Privacy & Security : AI handling personal data must comply with laws like GDPR & CCPA.
- AI Model Drift – Over time, AI performance may decline due to changes in user behavior or market trends.
Maintaining AI Systems After Deployment
AI isn’t a one-time project—it needs constant updates!
- You should regularly retrain AI models with new data.
- After deployment we got the work to do, fix bugs and optimize performance based on real-world feedback.
- Keep on tracking AI impact on business goals (e.g., has revenue increased? Are customer complaints reduced?).
Example:
The AI is deployed into the retail platform, helping store managers order the right products at the right time.
Conclusion
The AI Project Cycle ensures AI models are built, trained, and optimized for real-world applications. By following this structured process, businesses can develop AI systems that drive efficiency, boost automation, and improve decision-making.
Points to be Noted :
- Start with a well-defined AI problem.
- Use high-quality, structured data for better learning.
- Choose the right AI model and fine-tune it continuously.
- Deploy AI and monitor its performance regularly.
Let me tell you that mastering the AI Project Cycle will help you build powerful AI applications that create real impact!
FAQs
The AI Project Cycle is a step-by-step process used to develop AI models, covering problem identification, data collection, training, evaluation, and deployment.
It ensures AI models are efficient, accurate, and scalable, reducing errors and improving decision-making.
The AI Project Cycle consists of six stages: Problem Identification, Data Collection, Data Processing, Model Training, Model Evaluation, and Deployment.
Model selection depends on data type, complexity, and business goals. Popular models include decision trees, regression algorithms, and deep learning networks.
After deployment, AI models require constant monitoring and updates to maintain accuracy and adapt to new data.